15 JUL 2025 · 5 MIN READ
Kafka Essentials

Kafka is a message stream that holds the messages. Internally Kafka has topics.
Every topic has 'n' partitions. Message is sent to a topic and depending on the configured hash key, it is put into a partition.
Within partition, messages are ordered → no ordering guarantee across partitions.
When you increase number of partitions, existing messages stay as is - no messages would be sent to them.
what you'll take away
quick pointers so you know what to look for as you read:
- partition count is a one-way door. you can increase but never decrease, and existing data is never rehashed.
- partitions cap your parallelism. a consumer group can never have more active consumers than partitions.
- ordering lives inside a partition, nowhere else. same key → same partition → strict order. no global ordering.
- you don't delete messages, you commit offsets. "i've read till here" — and when you commit decides your delivery semantics.
- retention is a deadline, not housekeeping. consumers that lag past it lose messages silently, so size it with buffer.
Key Kafka Concepts
Message Distribution: When you send a message to a topic, the message is sent to one of the partitions based on:
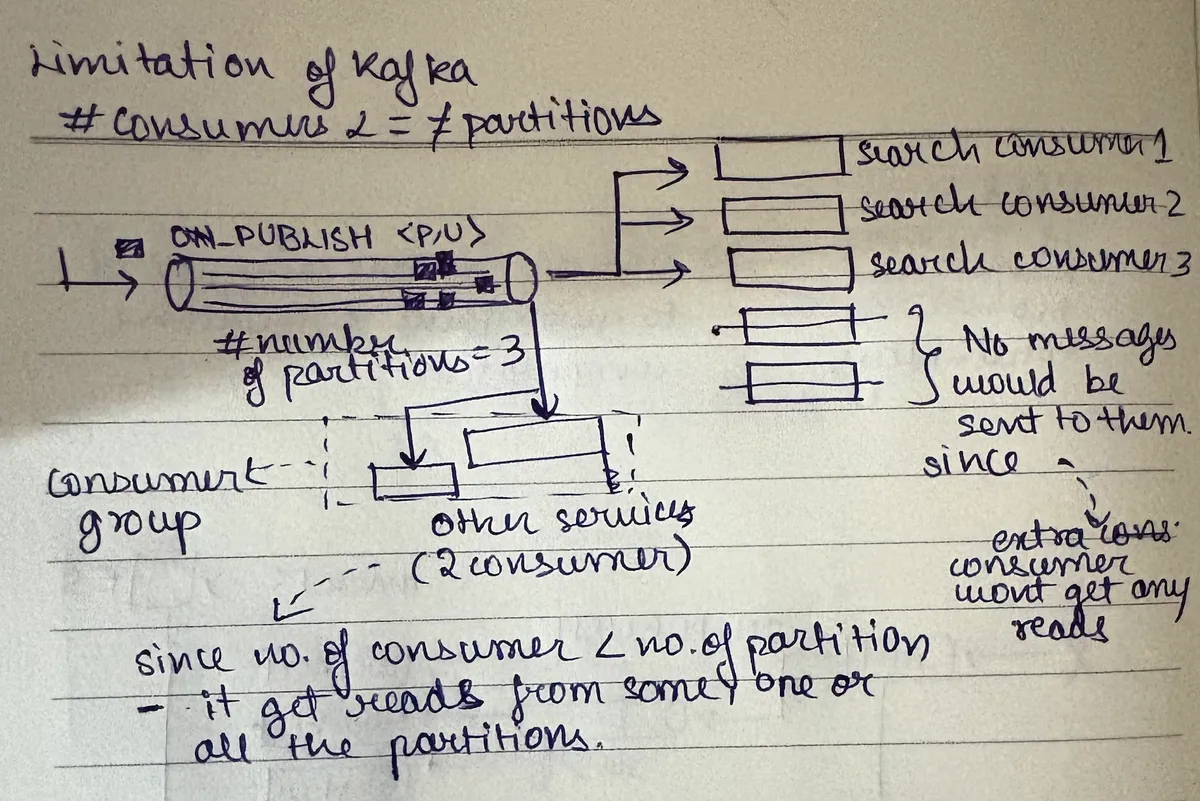
partition = hash(partition_key) % number_of_partitionsLimitation of Kafka: You cannot reduce the number of partitions (proposal for more consumers).
number_of_consumers <= number_of_partitionsFor more consumers, you need more partitions:
- If you have 3 partitions, you can have at max 3 consumers in a consumer group
- If you have 3 partitions but only 2 consumers → one consumer would own 2 partitions, another would own 1 partition
- If you have more consumers than partitions → extra consumers would not get any messages
When you increase partitions:
- You cannot reduce them again - so when increasing partitions make sure you take a number that's not too much, not too less for your current scale
- Existing data is not rehashed - the new partitions are created empty, hash function changes so new messages might go to new partitions
Gets records from one/some/all partitions (assigned).
✽ RECALL you bump a topic from 3 to 6 partitions. what happens to existing messages, and why should you think hard before doing it?
existing messages stay exactly where they are — kafka never rehashes old data, the new partitions start empty. but hash(key) % n changes, so new messages for a key may land on a different partition than its older ones. and you can never reduce the count again — it's a one-way door, so pick a number sized for your current scale, not too much, not too less.
✽ RECALL you add a 4th consumer to a group reading a 3-partition topic. what does it get, and what does that tell you about scaling consumption?
nothing — each partition is owned by exactly one consumer in a group, so 3 partitions means at most 3 active consumers and extras sit idle. partition count is your parallelism ceiling, and since you can't shrink it later, you scale consumption by planning partitions ahead, not by throwing more consumers at the topic.
Ordering Guarantees
- No global ordering across partitions
- Ordering guaranteed within a partition - all messages inserted in a partition are consumed in order of insertion
- One partition assigned to one consumer but one consumer can handle multiple partitions
✽ RECALL you need all events for a given user processed in order, but the topic has many partitions. how do you get that, and what ordering do you give up?
use the user id as the partition key — hash(key) % partitions routes every message for that user to the same partition, where insertion order is preserved and a single consumer owns it. you give up any ordering across partitions: that's the deal kafka offers — per-key order plus parallelism across keys, never global order.
Commit & Data Deletion
Commit: How do you tell Kafka that you have processed a message? You don't delete messages here (like in SQS). What you do is you say "hey I've read till this point" or "I commit till this message" so next time when a consumer from that consumer group wakes up, it gets messages from that point onwards.
Auto commit configuration is available, but the goal is you commit after you're done processing (or before, as per what you are building).
Data deletion: Because there's no delete API, Kafka has a data deletion policy which says "I'll delete a message older than 7 days, 14 days, 30 days" - you configure your retention period.
You need to know:
- How many messages you're receiving
- Your storage capacity
- How long it would take to fill storage
- Then decide retention policy
You expect your consumers to process messages within the retention period. So you set retention period with buffer - if you expect processing within 14 days, set retention to 30-40 days.
✽ RECALL kafka has no delete api like sqs. how do you tell it you're done with a message, and what changes if you commit before vs after processing?
you commit an offset — "i've read till this point" — per consumer group, and the next consumer in that group resumes from there. commit before processing and a crash loses the message; commit after and a crash means reprocessing it. neither is wrong — you place the commit based on what you're building.
✽ RECALL how do you size a retention period, and what's the failure mode if you guess too low?
messages are deleted purely by age, so if consumers lag past retention, unprocessed messages vanish silently — there's no warning and no recovery. work out how many messages you receive, your storage capacity, and your worst-case processing time, then set retention with a generous buffer: expect processing within 14 days, set 30–40.