05 APR 2026 · 16 MIN READ
bit.ly system design — building a url shortener
every system design conversation eventually circles back to bit.ly. it's the canonical "looks dead simple but isn't" service — take a long url, hand back a short one, redirect on click. the surface is straightforward. then you start asking how it scales to a billion urls and 100M daily active users, and the design gets way more interesting.
this is a full walkthrough — requirements, api, the dumb-first-design, then the deep dives where things actually get fun. i'm gonna walk through it as if i'm building it myself, talking through each decision as it comes up.
what you'll take away
quick pointers so you know what to look for as you read:
- the read/write asymmetry is wild. 1000:1 reads-to-writes. design around reads first.
- counter + base62 is the cleanest short-code generator. no collision checks, no extra reads.
- 6 base62 chars get you 56 billion urls. plenty of room for the next decade.
- redis as a counter is the secret weapon. single-threaded, atomic incr — perfect for this.
- counter batching kills the cross-network latency. grab 1000 ids at a time, use them locally.
- 302 redirect, not 301. keeps control on our side, allows analytics, doesn't get cached forever.
- boring is fine. postgres, redis, a load balancer. nothing fancy is needed for this whole system.
what we're building
a url shortener. user sends in https://www.example.com/some/very/long/url, we hand back something like short.ly/abc123. anyone who hits that short url gets bounced to the original. plus a couple of optional flavors:
- custom alias — user picks the short code (
short.ly/evan) - expiration time — short url stops working after a date
scope-wise we're skipping user accounts, click analytics, and spam detection. they add complexity without changing the core architecture.
what the system has to do
requirements come in two flavors. functional — the features. non-functional — the qualities.
functional:
- create a short url from a long url, optionally with custom alias and expiration
- redirect from short url to the original
non-functional:
- short codes are unique. one short code maps to one long url, no collisions ever.
- redirects feel instant — under ~200ms end to end.
- 99.99% available. we lean availability over consistency.
- handles 1B short urls total and 100M daily active users.
now the most important fact about this whole system, the one that drives every architectural decision later: read/write traffic is wildly asymmetric. one user creates a short url, then potentially millions click it. typical ratio is 1000 reads per 1 write. caching strategy, service topology, database choice — all of it falls out of that single number.
✽ RECALL what single fact about a url shortener's traffic drives every other design decision, and what falls out of it?
the read/write asymmetry — roughly 1000 reads for every write, because one person creates a link and millions click it. once you internalize that, the architecture falls out: design the read path first (index, cache, maybe a cdn at the edge), split read and write services so the hot side autoscales alone, and let the roughly-one-write-per-second side stay tiny and boring.
core entities
before drawing boxes, name the things our system moves around.
- original url — the long thing the user gave us
- short url (or short code) — what we generated
- user — who created it
really two entities, since short and long urls live in the same row of the same table. user is auxiliary.
the api
two endpoints. one to shorten, one to redirect.
POST /urls
{
"long_url": "https://www.example.com/some/very/long/url",
"custom_alias": "optional",
"expiration_date": "optional"
}
→ { "short_url": "http://short.ly/abc123" }GET /{short_code}
→ HTTP 302 redirect to the original long urldead simple. no fancy verbs, no nested resources. one post, one get.
the dumb-first design
start as small as possible — client, server, database. that's it.
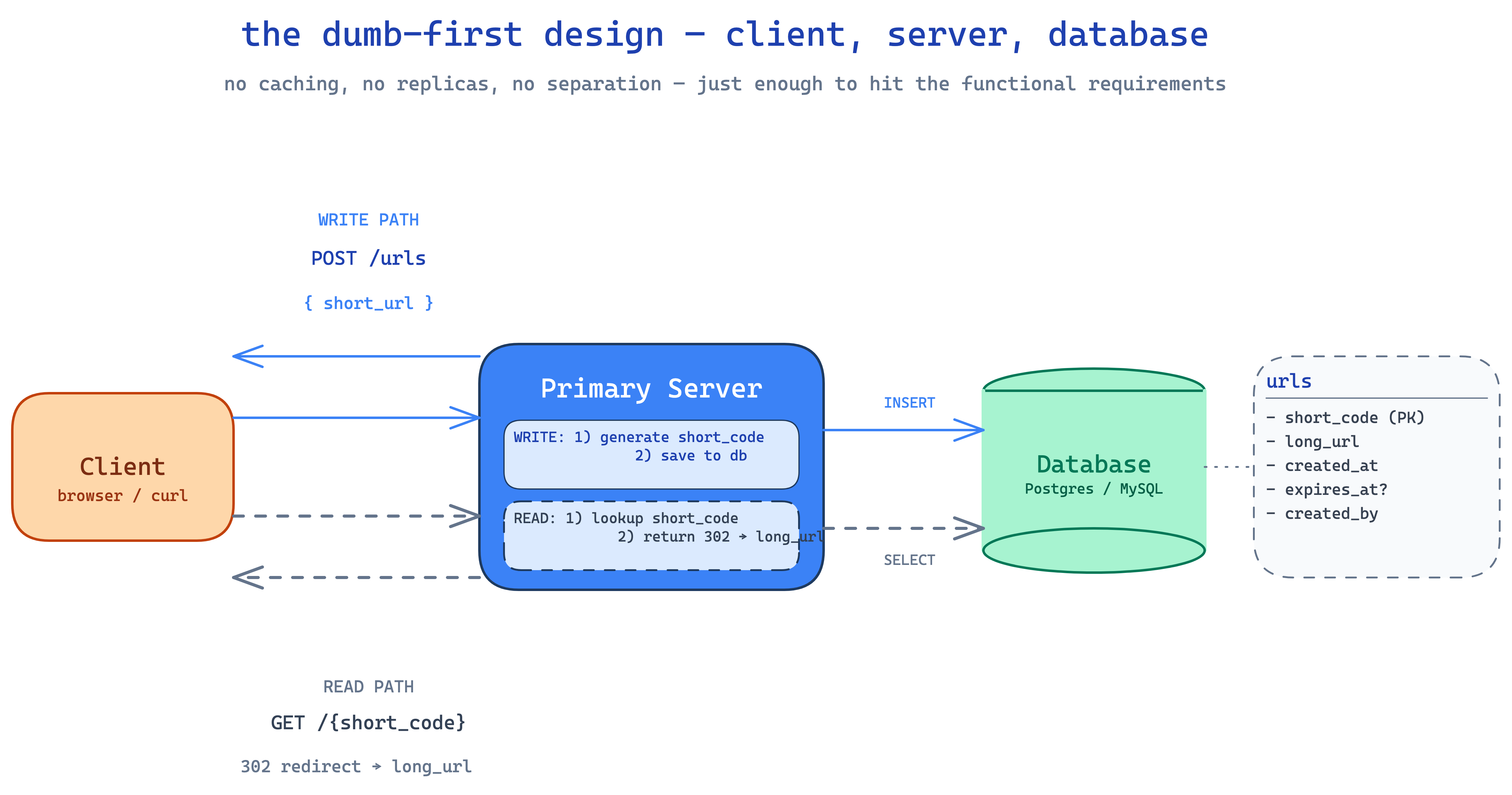
on a write:
- client
POSTs to the primary server with the long url - server validates the url (something like an
is-urlcheck) - server generates a short code (we'll get to how in a sec — this is the fun part)
- if the user gave us a custom alias, we use that — but we first check the db to make sure it's not already taken. nightmare scenario is a custom alias colliding with a generated code in the future. easy fix: prefix all generated codes with a character that aliases can't use, or keep them in different namespaces.
- server writes
(short_code, long_url, created_at, expires_at, created_by)to the db - server returns the short url to the client
on a read:
- user's browser hits
short.ly/abc123 - server looks up
abc123in the db - if it's there and not expired, server returns a
302 Foundwith the long url in theLocationheader - browser follows the redirect, user lands on the original site
- if expired, return
410 Gone. if missing entirely,404.
quick aside on 301 vs 302. 301 is "permanent" — browsers and intermediate caches will cache the redirect, future requests might never hit our server. 302 is temporary — every request comes through us.
we want 302. why?
- it lets us update or expire short urls without fighting browser caches
- if we ever want analytics (clicks, geo, referrer), every request needs to come through us
- the cost of a server hit per redirect is way smaller than losing observability
right, working system. the requirements aren't fully met yet though — we hand-waved short code generation, redirects aren't fast, we can't scale. let's actually get to the interesting parts.
✽ RECALL why return a 302 redirect instead of the "more correct" permanent 301?
a 301 gets cached by browsers and intermediaries, so future clicks may never reach your server — you lose the ability to update or expire short urls and you lose every click for analytics. a 302 keeps each request flowing through you: control, expiration, observability. the cost of one server hit per redirect is tiny next to going blind.
deep dive 1 — generating unique short codes
three properties we want:
- unique — never collide
- short — 5–7 characters
- fast to generate
let's walk a few options.
option 1: random + check
generate a random number, base62-encode it, slice the first 6 characters.
base62 encoding is a numbering system that uses 0-9, a-z, A-Z for 62 total symbols. 6 base62 characters gives 62^6 ≈ 56 billion combinations. lots of room.
problem: random isn't unique. how often will two random short codes collide? more often than you'd think. this is the birthday paradox in action — in a room of just 23 people there's already a 50% chance two share a birthday despite 365 possible birthdays. apply the same math to 1B short codes randomly chosen from 56B options and you get roughly 880k collisions. not catastrophic but not zero.
so we'd need a db check before saving — generate a candidate, look it up, if it exists try again, otherwise save. that adds a read on every write. not great.
option 2: hash the long url
hash(canonicalize(long_url)), take the first 6 base62 chars. md5, murmur, sha-256, whatever.
a good hash function has the avalanche property — change one bit on the input and the output looks completely different. so the collision behavior is the same as random: 56B possible outputs, same ~880k collisions at 1B urls. same db check needed.
what's nice about hashing — same long url always maps to the same short code, so we get deduplication for free. what's not nice — most url shorteners actually want multiple short codes per long url (different users want different aliases, different expirations, separate analytics). dedup is often a feature you don't want.
option 3: counter + base62 — the winner
just keep a counter. first url gets short code 1, second gets 2, third gets 3. base62-encode the counter to keep things compact.
the counter guarantees uniqueness by construction. no collision checks, no extra reads. the encoding keeps it short — at 1B urls, our short code is a 6-character string. quick math: 1,000,000,000 in base62 is 15ftgG. and 62^6 ≈ 56 billion, so we don't need to bump up to 7 characters until we cross that threshold (which would take a lifetime at any reasonable url shortener's growth rate).
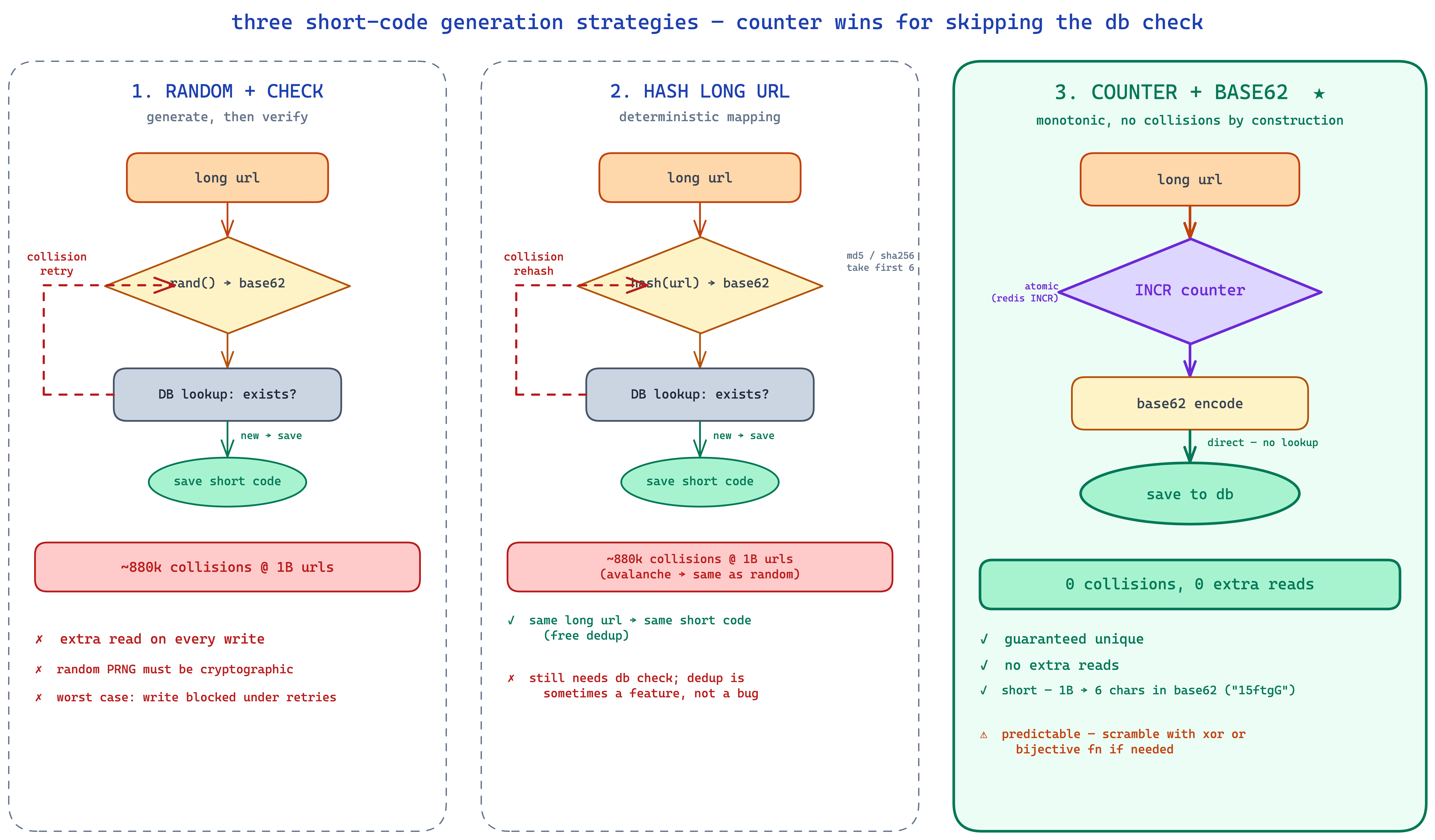
there's one fair concern with the counter: it's predictable. a competitor or scraper can iterate 1, 2, 3, ... and discover every short url we've generated. two ways to deal with this:
- accept it. short urls are usually meant to be shared publicly anyway. rate-limit and move on.
- scramble the counter before encoding. xor with a secret key, or use a "bijective" function (the squids library is one) that maps
1 → "Xa3kL9"reversibly but unpredictably. you keep the uniqueness, you lose the predictability.
we're going with the counter. cleanest, fastest, no read amplification on writes.
✽ RECALL why does counter + base62 beat random codes and hashing the long url for short-code generation?
random and hash both collide — birthday paradox, so at a billion urls you're looking at hundreds of thousands of collisions — which forces a db existence check before every save: read amplification on the write path. a counter is unique by construction, no checks at all, and base62-encoding keeps it short, with six characters covering tens of billions of codes. the one cost is predictability; either accept it (short urls are shared publicly anyway, rate-limit and move on) or scramble the counter with a bijective function before encoding.
deep dive 2 — making redirects fast
the read path is short_code → long_url. without optimization the server walks every row of the urls table on each lookup. at 1B rows that's a non-starter — full table scan for every redirect. dead.
step 1: index the short code
stick a primary key (or unique index) on short_code. now the database keeps a b-tree of short codes pointing to row locations on disk. lookups become O(log n) — typically a handful of memory reads followed by one disk seek to fetch the row.
postgres does this automatically for primary keys. for a WHERE short_code = ? lookup this is plenty fast — well under 10ms even at 1B rows.
step 2: cache the hot path
even with an index, every lookup eventually touches disk. and a huge fraction of our traffic is going to be a small number of viral short codes. that's a caching layup.
stick a redis (or memcached) instance in front of the db. on every read:
- check redis for
short_code → long_url - hit? return immediately — sub-millisecond
- miss? read from db, populate redis, return
eviction policy is least recently used — if the cache fills, kick whatever's been quiet longest. natural fit for url shorteners because old links go cold fast.
key: "abc123"
value: "https://www.example.com/long/url"dead simple key-value lookup. redis hits sub-ms, db hits maybe 10ms. for hot urls we basically never touch the database. tie the cache TTL to the url's expiration time so expired entries fall out automatically.
step 3 (optional): cache at the edge
for global users, even a redis hit means a round-trip to whatever region our service runs in. a user in tokyo hitting a virginia data center is eating 200ms just on the network.
a CDN (cloudflare, fastly, akamai) caches responses at edge servers worldwide. for popular short codes the redirect can be served from the tokyo edge in 10–20ms without ever reaching our origin.
trade-offs:
- cache invalidation across many edge nodes is harder
- you lose visibility — the request never hits your server, so analytics get weird
- it costs money
worth it for the most-clicked links and globally distributed audiences. for everything else, a single redis layer in your primary region is plenty.
deep dive 3 — scaling to 1B urls and 100M DAU
let's do the back-of-envelope math.
writes:
- 1B urls total over the lifetime of the service
- assume linear-ish growth → roughly 100k new urls per day
- that's
~1 url per secondaverage. peaks maybe 10x. easy.
reads:
- 100M DAU × 1 redirect/user/day ≈ 100M redirects/day
- 100M ÷ 86,400s ≈
1,200 reads/secaverage - peaks 10x or 100x →
12k – 120k reads/secat the upper bound
storage:
- per row: short_code (
8 bytes) + long_url (100 bytes) + timestamps (16 bytes) + custom_alias (100 bytes) + metadata (~80 bytes) ≈ 300 bytes. round up to 500. - 500 bytes × 1B rows =
500 GB. fits on a single modern instance with room to spare.
so the dataset isn't the problem. the read throughput is. and we already solved most of that with caching. let's wire up the rest.
split read and write services
reads and writes have completely different traffic profiles:
- writes:
~1/sec - reads:
10k+/sec, possibly bursting to 100k/sec
scaling them together is wasteful. we'll split them into two services behind an api gateway. the gateway routes POST /urls to the write service and GET /{short_code} to the read service.
each service horizontally scales independently. read service runs hot — many instances, all behind a load balancer, hitting redis cache and falling back to db. write service stays small — one or two instances handle the entire write load.
is splitting really worth it? honestly, for a service this small, sometimes no. running two services means two deployments, two dashboards, two on-call rotations. but the read/write asymmetry here is so extreme that the split is genuinely useful — you can autoscale the read service on cpu/memory thresholds without ever touching the write service.
the global counter problem
now that we've split into multiple write service instances, the counter has to live somewhere shared. you can't have each instance keeping its own count — they'd all hand out short_code 1 simultaneously.
the answer is a central redis instance holding the counter. redis is single-threaded, so its INCR command is atomic — two simultaneous calls always get different values. one gets 1000, the next gets 1001, never the same one twice.
every time the write service needs a new short code:
INCR counteron redis → returns next value- base62-encode it
- write
(short_code, long_url, ...)to the db - return short url to client
✽ RECALL multiple write instances each need globally unique ids. why is a single redis counter the answer, and what makes it safe?
redis is single-threaded, so INCR is atomic — two simultaneous calls can never receive the same value, which is exactly the uniqueness guarantee short codes need with zero coordination protocol. and a single redis box handles 100k+ ops/sec, while this system writes about one url per second — the counter is never the bottleneck. if redis loses a few values during failover, fine: the database's unique constraint is the safety net.
counter batching — kill the per-write network hop
doing a redis call on every single write is fine but wasteful. we can do better.
batch counter ranges to each write service instance. when a write service starts, it asks redis for a chunk of 1000 counter values:
INCRBY counter 1000 → returns N (start of the batch)the instance now owns counters N through N+999 locally. it serves urls from this range with zero cross-network calls. when it runs out, it asks for the next 1000.
if a write service crashes mid-batch, those unused counters are lost forever. who cares — 56 billion total slots, losing a few hundred is invisible. we just need uniqueness, not continuity.
✽ RECALL what does counter batching fix, and why is losing a batch when an instance crashes a non-issue?
it kills the per-write network hop — instead of hitting redis for every url, an instance grabs a range of ids with one INCRBY and burns through them locally, refilling when empty. a crash loses the unused remainder of the batch, and nobody cares: you need uniqueness, not continuity, and the base62 keyspace has tens of billions of slots to spare.
multi-region — split the counter space
if the service runs in multiple regions (US, EU, APAC), having every region hit a single global counter is a latency disaster. instead, partition the counter space so each region owns a slice:
- US gets
[0, 1B) - EU gets
[1B, 2B) - APAC gets
[2B, 3B)
each region runs its own redis with its own slice of the namespace. no cross-region coordination on the hot path. a UNIQUE constraint on short_code in the database is the ultimate safety net if anything ever drifts.
the database
we said 500 GB on a single instance. that's fine for postgres or mysql today — vertically scale to instances with multi-TB SSDs and hundreds of GB of ram easily. so we don't actually need to shard.
if we ever do need to shard (say, data grows past 5 TB), we'd shard by short_code — hash(short_code) % N to pick a shard. but for the next decade of growth, one well-tuned postgres handles this whole system.
high availability matters though. one box dying takes down the entire product. so:
- read replicas for redundancy and to absorb db reads if redis ever goes cold
- regular snapshots to s3 (or equivalent) for point-in-time recovery
- automatic failover — if the primary dies, promote a replica
for redis (counter and cache), redis sentinel or cluster mode handles failover. if redis loses the latest counter values during a failover, we lose a few short codes — fine, the database's unique constraint catches anything that would actually collide.
the final design
zooming out, here's everything wired together.
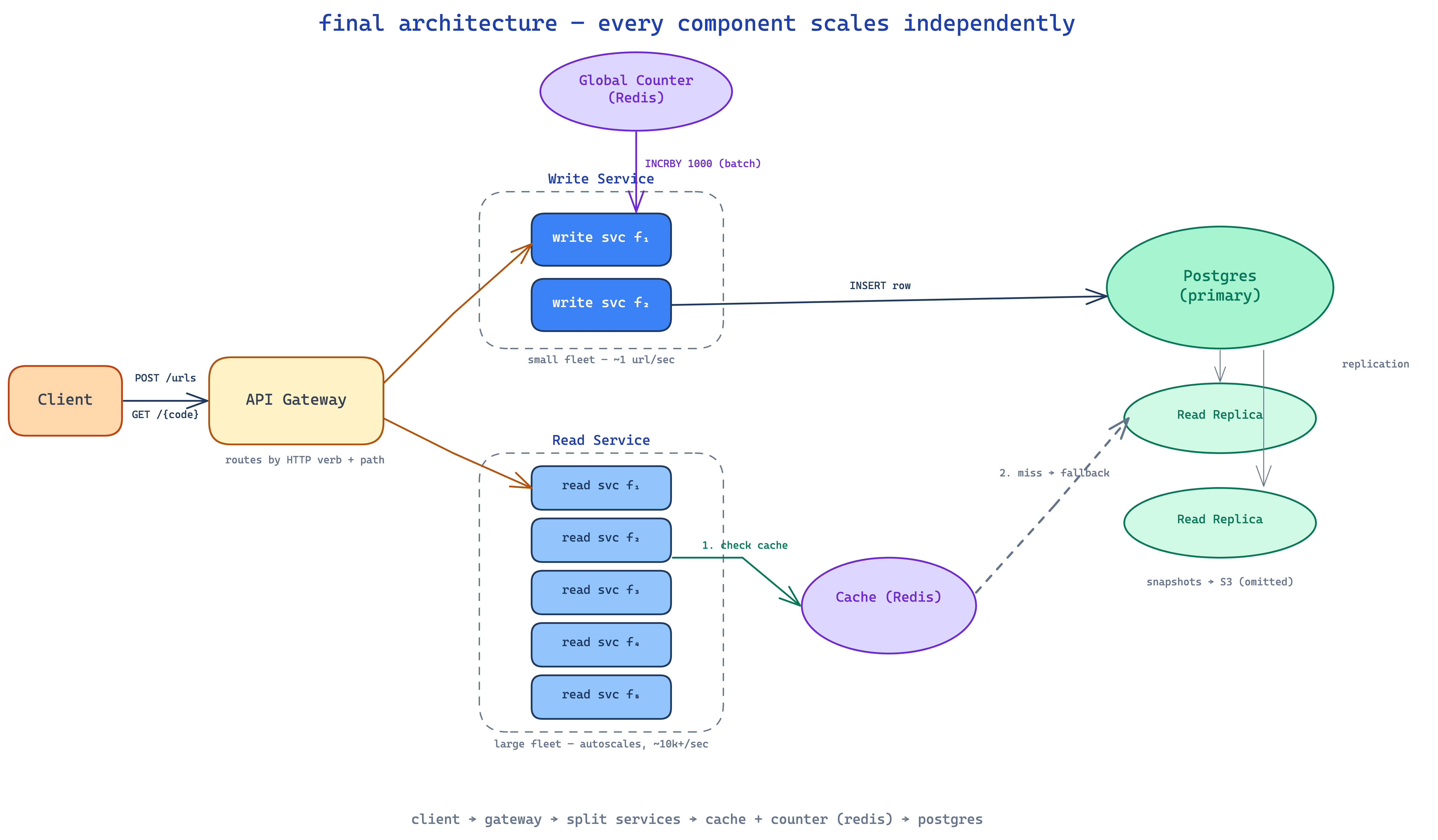
- client hits the api gateway
- gateway routes writes to the write service (small fleet)
- write service grabs a counter value (from its local batch, refilling from the global counter redis when empty)
- base62-encodes it, writes the row to the postgres database
- gateway routes reads to the read service (large fleet)
- read service checks the redis cache first
- on miss, reads the database, populates cache, returns
- read service responds with
302and the long url - browser follows the redirect
every component scales independently. read service autoscales on traffic spikes without touching writes. cache absorbs the hot path. database serves only cache misses. counter is durable, atomic, and never a bottleneck thanks to batching.
✽ RECALL what's actually "fancy" in the final bit.ly design — and what should that teach you?
nothing — postgres, redis, an api gateway, a load balancer. the one structural flourish, the read/write service split, is earned by the extreme traffic asymmetry; everything else stays deliberately boring. no sharding for a dataset that fits one box, no microservices for a one-write-per-second workload. boring components, well arranged, carry a billion urls — you're paid to solve a problem, not to ship the fanciest architecture.
what i'd take away from all this
a few thoughts after walking through it.
- start with the asymmetry. reads vs writes is the lens through which every other decision is made. once you internalize 1000:1, the cache, the service split, the counter — they all just fall out.
- counter + base62 is the answer for short-code generation in 99% of these systems. it skips the collision-check tax that random and hash approaches need.
- single redis is enough. for the counter, for the cache, for everything in this system. redis at 100k+ ops/sec on a single box is more than this whole service needs.
- microservices for a tiny system are theater. the read/write split here is justified by the traffic asymmetry, but a lot of designs split for the sake of splitting. don't.
- boring is fine. postgres, redis, an api gateway, a load balancer. nothing here is novel — and that's the whole point.
nothing is best. everything depends on the actual traffic, the actual constraints, the actual money. but for a url shortener at this scale, this design holds up. you're paid to solve a problem, not to ship the fanciest architecture.