07 MAY 2026 · 11 MIN READ
how dropbox handles uploads, downloads and sync
dropbox is one of those apps that feels totally simple until you start designing it. you upload a file, it shows up on your other devices. share it, someone else sees it. but every step here has a real engineering question buried in it. 50GB uploads can't just be a single POST. sharing 100k files across users can't just be a list scan. and getting bytes from a virginia data center to a tokyo client without making them wait 30 minutes? that's a whole separate problem.
this post walks through how i'd actually build it.
what you'll take away
quick pointers so you know what to look for as you read:
- never upload large files through your own servers. presigned URLs let the client upload directly to S3.
- chunk + fingerprint = resumable uploads. a hash of each chunk gives you a unique id that works across sessions.
- trust but verify. clients report progress, but the server confirms via S3's
ListPartsbefore marking done. - sharing is a graph problem, not a list problem. put
(userId, fileId)in its own indexed table. - sync is a hybrid. WebSocket push for near-real-time, polling as the safety net.
- CDN for downloads, not uploads. downloads benefit from edge caching; uploads don't.
- content-defined chunking is the secret of delta sync. fixed boundaries break the moment you insert a byte at the start.
what we're building
a cloud file storage service. user uploads a file, downloads it from any device, shares with others, and sees automatic sync across all their connected devices.
scope:
- upload, download, share, automatic sync across devices
- support files up to 50GB
- low latency, secure, available
out of scope:
- file editing, in-app preview, virus scanning, versioning, per-user storage limits
- rolling our own blob storage (we'll use S3 / equivalent and call it done)
the cap call
availability > consistency. user uploads a file in germany; user in america seeing the old version for a few seconds is fine. dropbox is not a stock exchange. eventual consistency, no problem.
core entities
just two real entities and a user wrapper:
- File — the raw bytes
- FileMetadata — id, name, size, mime type, owner, status, s3 link, chunks
- User — auxiliary, identified via session token / JWT in headers
the api
four endpoints, one per feature:
POST /files/presigned-url → returns a presigned URL to upload to
GET /files/{fileId} → returns metadata + presigned download URL
POST /files/{fileId}/share → body: { users: [...] }
GET /files/changes?since=... → returns ChangeEvent[] for delta syncusers come from headers, never from request bodies — keep auth out of payloads.
upload — the presigned URL trick
the obvious way to handle uploads is wrong, and it's worth saying why.
if a user POSTs a 50GB file to your server, two bad things happen. first, you've burned bandwidth uploading the file twice — once from client to your server, once from your server to S3. second, your API gateway probably has a 10MB request body limit (looking at you, AWS API Gateway). you can't even get the bytes through the gate.
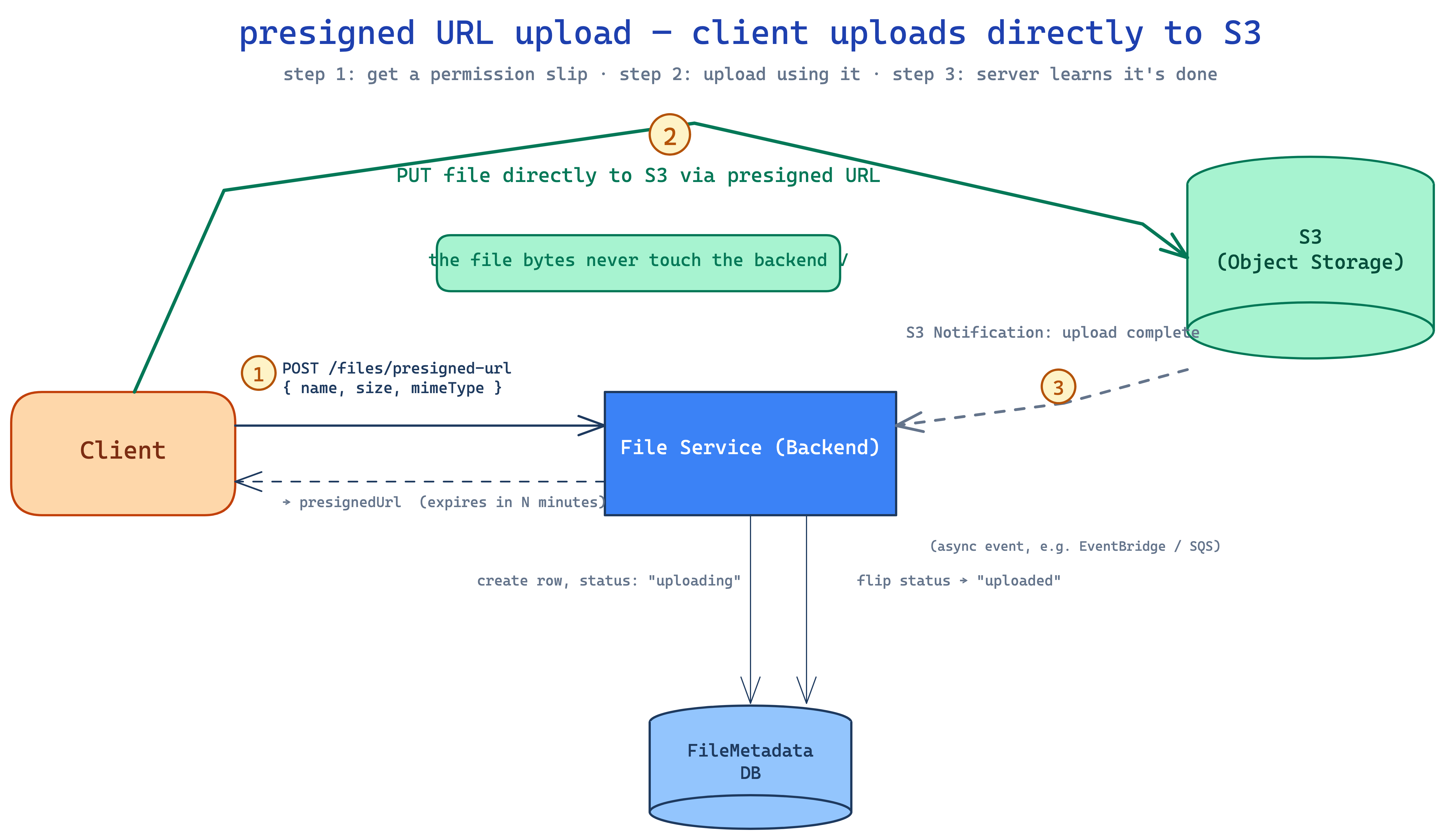
the fix is presigned URLs. instead of the file flowing through your server, the client requests a permission slip from your server, then uploads directly to S3 using that slip.
three steps:
- client POSTs to
/files/presigned-urlwith just the metadata (name, size, mimeType). server creates a row inFileMetadatawithstatus: uploading, generates a presigned URL via the S3 SDK, returns the URL. no file bytes touch your server. - client PUTs the file directly to the presigned URL. S3 stores it.
- S3 fires an event notification to your backend on completion. backend flips
status: uploaded.
now your server never holds the bytes. the file goes client → S3 directly. cheap, fast, no payload limits.
download — the same trick, in reverse
same idea. client requests metadata from your server, server returns a CDN-signed URL pointing to the file. client fetches from the CDN; CDN serves from cache or pulls from S3 on first miss.
GET /files/{fileId} → { metadata, downloadUrl }the downloadUrl is a signed CDN URL with a short expiration (5 minutes is typical). without that signature, anyone with the link could download. with it, the CDN verifies the signature and serves only authorized requests.
✽ RECALL why should neither uploads nor downloads of file bytes flow through your api servers — and why does the download path add a CDN while the upload path doesn't?
proxying a 50GB upload burns the bandwidth twice (client → your server, your server → S3) and your api gateway's request body limit blocks the bytes anyway. so the server issues a presigned URL, the client PUTs directly to S3, and an S3 event notification flips the metadata to uploaded. downloads reverse the trick: the server returns a short-TTL signed CDN url, because hot files benefit from edge caching. uploads skip the CDN because fresh unique bytes have nothing to cache.
large files — chunk, fingerprint, resume
50GB on a 100Mbps connection takes ~1 hour. asking the user to start over if their wifi drops 45 minutes in is cruel. and honestly, most browsers and servers won't even accept a single request that large.
the answer is chunking on the client. break the file into 5–10MB pieces. upload each chunk separately. track progress by counting completed chunks. resume by skipping chunks already uploaded.
but how do you know which chunks have been uploaded? you can't go by file name — two users can upload files with identical names. you need a content-derived id. that's a fingerprint — a SHA-256 (or similar) hash of the bytes.
so the metadata grows:
{
"id": "uuid-123",
"fingerprint": "sha256:ab12...",
"name": "movie.mp4",
"status": "uploading",
"chunks": [
{ "id": "chunk-1-fp", "status": "uploaded", "etag": "..." },
{ "id": "chunk-2-fp", "status": "uploading" },
{ "id": "chunk-3-fp", "status": "not-started" }
]
}when the client resumes, it computes the file fingerprint, asks the server "have we seen this?", gets back the chunks array, and uploads only the missing ones.
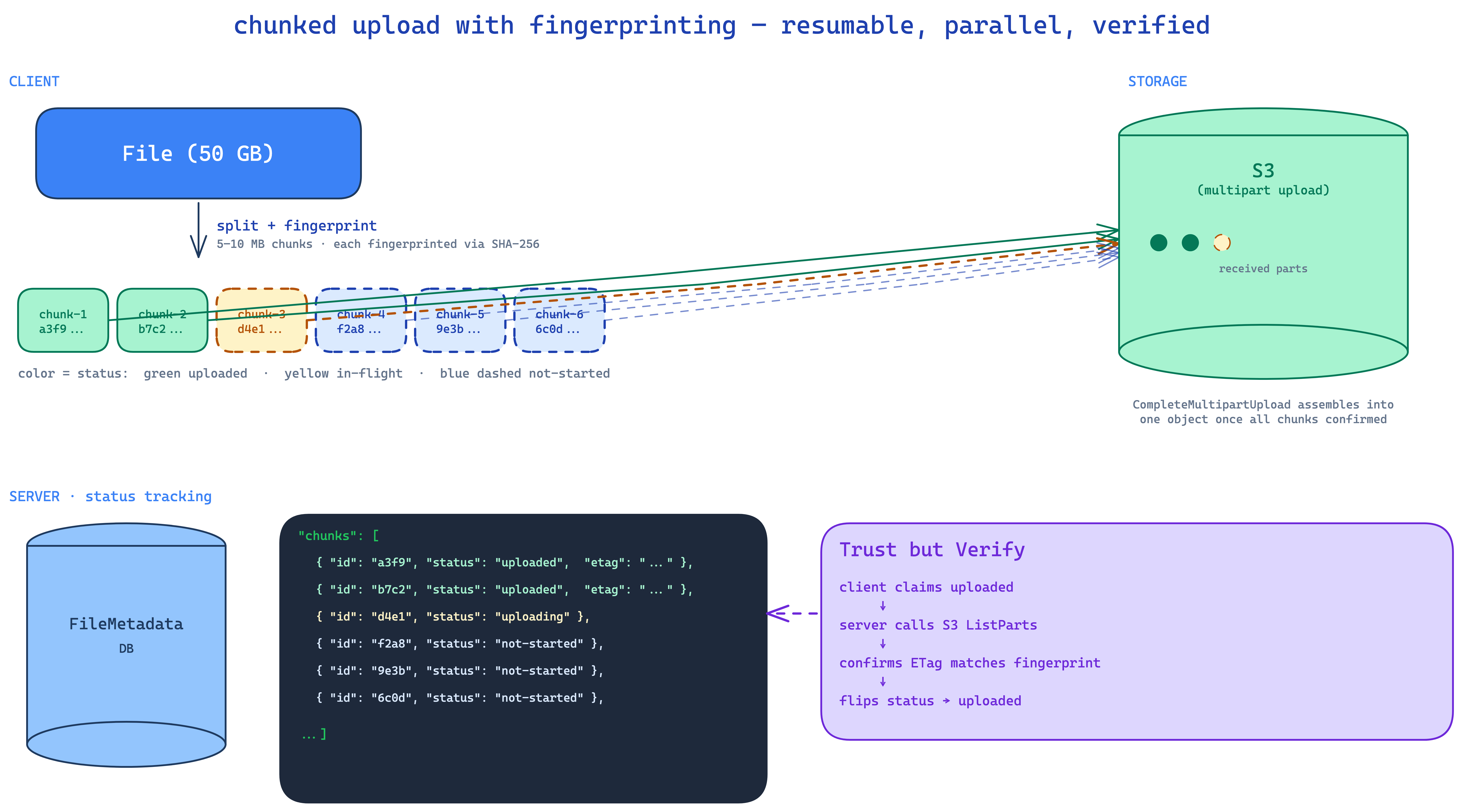
✽ RECALL your 50GB upload dies 45 minutes in. what makes resume possible, and why can't file names do the job?
the client chunks the file into 5–10MB pieces and ids each one by a fingerprint — a hash of the chunk's bytes. on resume it recomputes the file fingerprint, asks the server "have we seen this?", gets back the chunk statuses, and uploads only the missing ones. names can't work — two users can upload identically-named files. content-derived ids are unique and survive across sessions, which is also what makes chunking solve request-size limits, resumability, and parallelism in one shot.
trust but verify
how does the server know a chunk was actually uploaded? naive answer: client sends a PATCH after each chunk completes. problem: a malicious client can lie. they could mark all chunks uploaded without uploading any, leaving you with metadata that says "complete" pointing at empty S3 objects.
the fix is trust but verify. when the client claims chunk N is uploaded with ETag X, your backend calls S3's ListParts API to confirm. only after S3 vouches do you flip the chunk to uploaded. once all chunks check out, call CompleteMultipartUpload to assemble them into a single S3 object.
S3's multipart upload API basically packages this whole flow. you can use it directly, but knowing what's underneath makes the trade-offs visible.
✽ RECALL the client PATCHes "chunk 3 uploaded, here's the ETag". why don't you just believe it, and what do you do instead?
a malicious client can mark every chunk uploaded without sending a byte, leaving metadata that says "complete" pointing at empty S3 objects. trust but verify: on each claim the backend calls S3's ListParts to confirm the chunk actually landed, and only then flips its status. once every chunk checks out, CompleteMultipartUpload assembles them into one object. it's the clean general pattern for client-reported state on a hostile network.
sharing — separate table, not a list field
the obvious approach is to add a sharelist: [user1, user2] field to file metadata. it works for "is this user allowed?" but it falls apart on the inverse query: "show me everything shared with me." you'd have to scan every file's sharelist looking for the user. terrible.
put it in its own table:
SharedFiles
| userId (PK) | fileId (SK) |
| user1 | fileId1 |
| user1 | fileId2 |
| user2 | fileId3 |now both directions are O(1). "show me everything shared with me" is a single index lookup on userId. "is user X allowed?" is a single point read on (user, fileId). cheap.
✽ RECALL why does a sharelist: [user1, user2] field on file metadata fall apart, and what replaces it?
it answers "is this user allowed?" just fine, but the inverse query — "show me everything shared with me" — forces a scan of every file's sharelist. put the relationship in its own SharedFiles table keyed (userId, fileId): now both directions are a single index lookup. sharing is a graph problem, not a list problem — model the edge, not an attribute.
sync — push + poll hybrid
every connected device needs to know when files change. two options:
- polling — client asks "anything new?" every N seconds. simple, can lag, wastes calls when nothing changed.
- WebSocket / SSE — server pushes change events to the client in real-time. fast, but connections drop and you can miss messages.
dropbox uses both. WebSocket as the primary path, polling as the safety net.
the client opens a single WebSocket per device (not per file). the server pushes change notifications for any file the user has access to. if the WebSocket drops or messages get lost, the client is also calling GET /files/changes?since={timestamp} every few minutes. anything missed by the push gets caught by the poll.
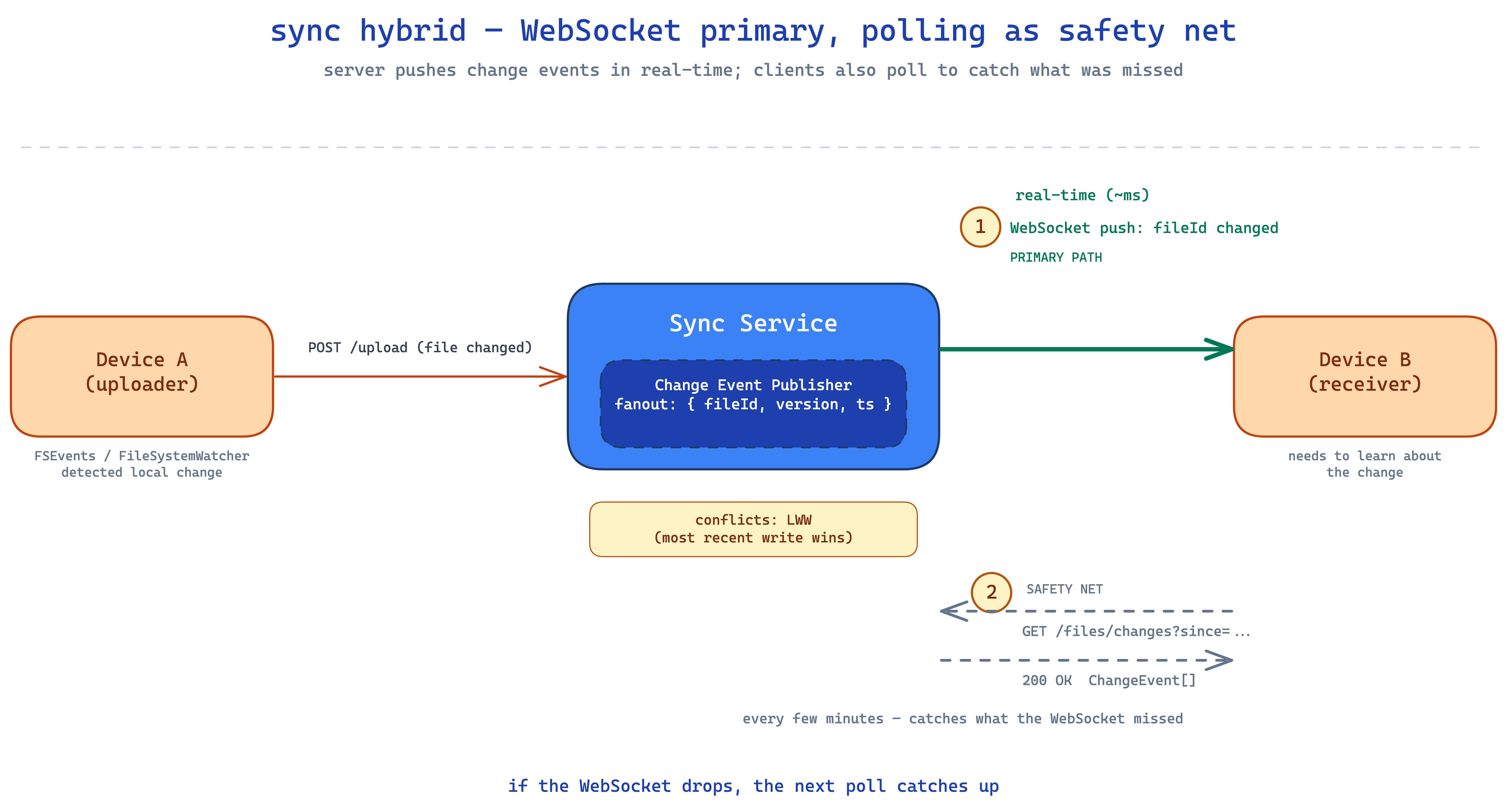
on the local side, each OS gives you a file watcher (FSEvents on macOS, FileSystemWatcher on windows). when something changes locally, the client agent uploads it to remote. last-write-wins for conflicts.
✽ RECALL why does dropbox run polling alongside websockets instead of trusting the push path alone?
sockets drop and messages get lost. the client keeps one websocket per device (not per file) for near-real-time pushes of any file it can access, and also calls GET /files/changes?since=... every few minutes as a safety net — anything the push missed, the poll catches. push for latency, poll for correctness; conflicts resolve last-write-wins.
delta sync — only ship the chunks that changed
once chunking is in place, sync gets a free win: when a file changes, we only need to upload (or download) the chunks that actually changed, not the whole file.
but there's a subtlety. if you chunk by fixed sizes (every 5MB), inserting a single byte at the start of the file shifts all chunk boundaries. now every chunk's fingerprint is different. delta sync becomes useless.
the fix is content-defined chunking (CDC) — chunk boundaries are determined by the file's content using a rolling hash (Rabin fingerprinting). a byte inserted near the start only affects the chunks immediately around it; the rest stay identical. this is how real systems achieve actual delta sync efficiency.
✽ RECALL you insert one byte at the start of a synced file. why does fixed-size chunking force a full re-upload, and how does content-defined chunking avoid it?
with fixed-size chunks every boundary shifts by one byte, so every chunk's fingerprint changes and delta sync degenerates into shipping the whole file. CDC picks boundaries from the content itself via a rolling hash (rabin fingerprinting), so an edit only changes the chunks immediately around it — everything else keeps its fingerprint and never moves. that's what makes dropbox feel fast on edits.
the final wiring
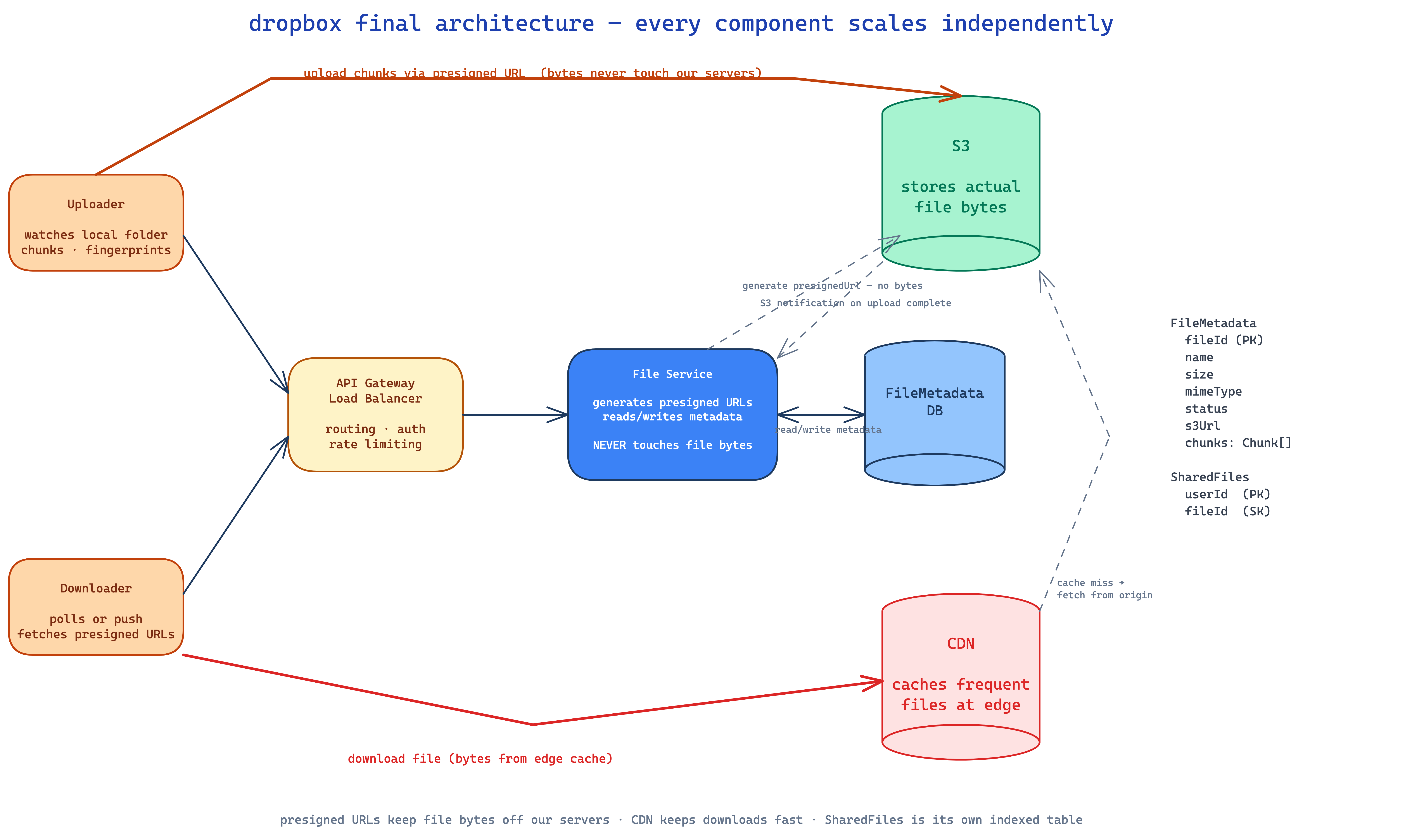
what each component does:
- uploader — client agent. watches local folder via OS file events, chunks files, computes fingerprints, calls the upload API.
- downloader — client. polls or receives push notifications, fetches presigned URLs, downloads from CDN.
- API gateway — auth, rate limit, route.
- file service — generates presigned URLs (purely local, signs with AWS credentials), reads/writes metadata. never touches file bytes.
- file metadata DB — DynamoDB or Postgres, doesn't matter much. holds
FileMetadataand theSharedFilestable. - S3 — holds the actual file bytes.
- CDN — caches files at edge locations for fast downloads, serves via signed URLs.
security in two minutes
- TLS everywhere — HTTPS for all traffic, end of story.
- encryption at rest — S3 encrypts files transparently with managed keys.
- signed URLs with short TTLs — even if a download URL leaks, it expires in 5 minutes. for higher security, bind URLs to specific IPs or require auth cookies.
- compress before encrypting — encryption introduces randomness, killing compression ratios. always compress first.
what i'd remember
- presigned URLs are the entire point of file upload design at scale. never proxy bytes through your server.
- chunking solves three problems at once — request size limits, resumability, parallelism.
- fingerprints are content-derived ids. use them everywhere — for files, for chunks, for dedup.
- trust but verify is the clean way to handle client-reported state on a hostile network.
- sync is a hybrid problem. push primary, poll fallback.
- CDC > fixed chunking for delta sync. the rolling hash trick is what makes dropbox feel fast on edits.
nothing here is novel. S3 multipart upload, presigned URLs, signed CDN URLs, file watchers — it's all off-the-shelf. the design is in the wiring. you're paid to solve a problem, not to ship the fanciest architecture.